LLM Setup

The AI Test Agent leverages Large Language Models (LLMs) to automatically generate fuzz tests for your project. To enable this feature, you need to grant the agent access to a supported LLM provider.
The ability of CI Fuzz to generate good quality fuzz tests correlates with the coding capabilities of the connected LLM, therefore, it is best used in conjunction with best-in-class models and large context sizes.
Currently, the AI Test Agent supports models from OpenAI, Microsoft Azure, and Anthropic on AWS Bedrock, including popular models like GPT-5 and Claude 4.5 Sonnet. Experimental support is available for local hosting solutions like Ollama.
Configuration
You can configure the LLM integration by adding an llm section to your cifuzz.yaml file. This is the recommended way to set up the connection to your LLM provider.
Here is an overview of the available configuration options:
| Option | Description | Required | Default |
|---|---|---|---|
api-type | The LLM provider: open_ai, azure, azure_ad, or bedrock. | Yes | - |
model | The specific model name (e.g., gpt-5). | Yes | - |
api-url | The base URL for the API (required for Azure). | No | Provider default |
api-version | The API version (required for Azure). | No | Provider default |
azure-deployment-name | The deployment name on Azure. | No | - |
max-tokens | The maximum number of tokens for a single chat completion request. | No | Provider default |
timeout | The timeout for LLM API responses (e.g., 10m, 30s). | No | 10m |
For a persistent configuration that applies to all your projects, you can set these options in your global user configuration file. See the Configuration page for more details.
Provider Setup
Below are instructions for configuring each supported LLM provider.
OpenAI
-
Get an API Key: Follow the OpenAI documentation to obtain an API key.
-
Set the API Key: Store your key in the
CIFUZZ_LLM_API_TOKENenvironment variable:export CIFUZZ_LLM_API_TOKEN="<your-openai-api-key>" -
Configure
cifuzz.yaml: Add the following to yourcifuzz.yamlfile.llm:
api-type: "open_ai"
model: "gpt-5"
OpenAI on Azure
Azure OpenAI supports two authentication methods: API key authentication and Azure Entra ID (formerly Azure Active Directory) authentication.
- Deploy a Model: Deploy a model like GPT-5 in Azure AI Studio. For details, see the Azure AI Services documentation.
Azure with API key authentication
-
Get Credentials: From your deployment in Azure AI Studio, you need the endpoint URL, API key, and deployment name.
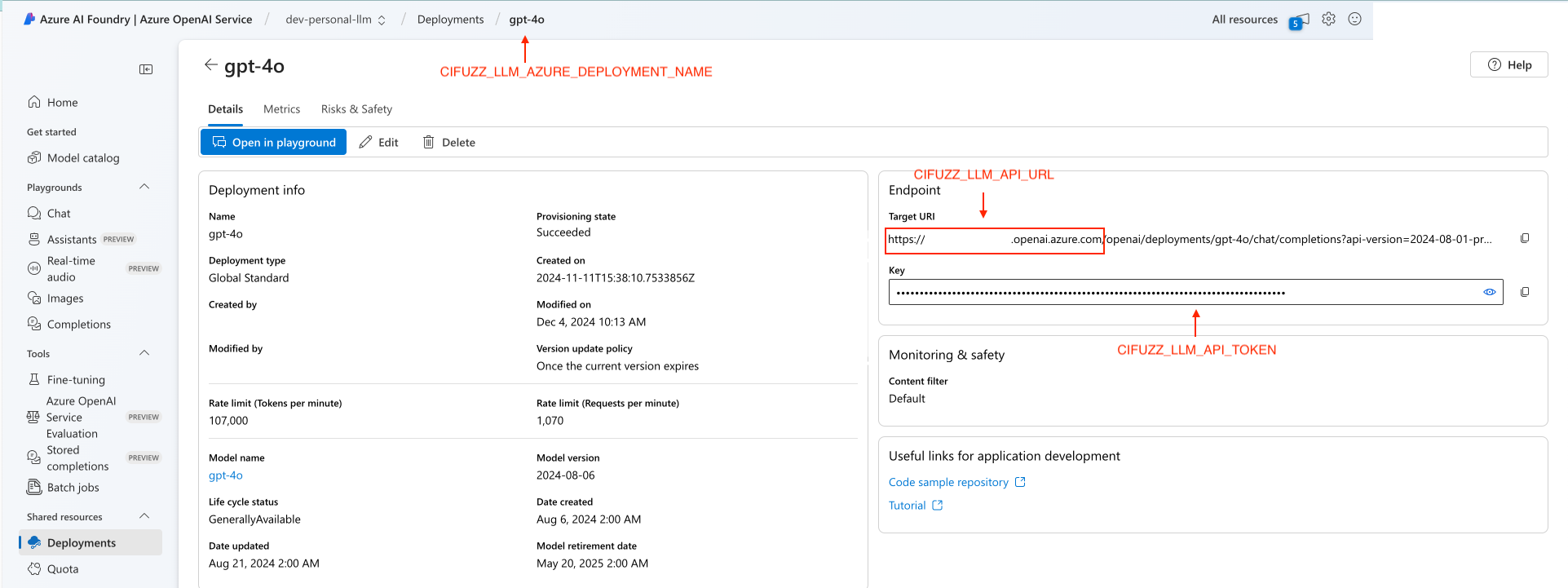
-
Set the API Key: Store your key in the
CIFUZZ_LLM_API_TOKENenvironment variable:export CIFUZZ_LLM_API_TOKEN="<your-azure-api-key>" -
Configure
cifuzz.yaml: Add the following to yourcifuzz.yaml, filling in the details from your Azure deployment.llm:
api-type: "azure"
model: "gpt-5" # The original model name, not the deployment name
api-url: "https://<your-resource>.openai.azure.com"
api-version: "2024-02-15-preview" # Use the API version for your deployment
azure-deployment-name: "<your-deployment-name>"noteThe
api-urlshould be the base URL of your Azure resource, ending in.openai.azure.com.
Azure with Entra ID authentication
For enhanced security, you can use Azure Entra ID (formerly Azure Active Directory) for authentication instead of API keys.
-
Set up Azure Entra ID authentication: Ensure users have the necessary permissions to access the Azure OpenAI resource. You can authenticate using:
- Azure CLI: Run
az loginto authenticate with your Azure account. - Managed identities: Use a managed identity if the AI Test Agent runs on Azure resources.
- Service principals: Configure a service principal for non-interactive environments (like CI/CD pipelines or Docker containers).
- Azure CLI: Run
-
Configure
cifuzz.yaml: Add the following to yourcifuzz.yaml, usingazure_adas theapi-type:llm:
api-type: "azure_ad"
model: "gpt-5" # The original model name, not the deployment name
api-url: "https://<your-resource>.openai.azure.com"
api-version: "2024-02-15-preview" # Use the API version for your deployment
azure-deployment-name: "<your-deployment-name>"noteThe
api-urlshould be the base URL of your Azure resource, ending in.openai.azure.com.
Anthropic on AWS Bedrock
-
Enable Model Access: Follow the AWS Bedrock documentation to get access to Anthropic's Claude models (e.g., Claude 4.5 Sonnet).
-
Configure AWS Credentials: Make sure your environment is authenticated with AWS. You can do this by running
aws configureor by setting theAWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYenvironment variables. -
Configure
cifuzz.yaml: Add the following to yourcifuzz.yamlfile.llm:
api-type: "bedrock"
model: "anthropic.claude-sonnet-4-5-20250929-v1:0"
Experimental: Local models with Ollama
Requirements: Ollama installed and configured.
-
Download and deploy model: Run
ollama pull <model_name>.noteIn our experience, small (≤~30b parameter) coding models are not good enough to generate meaningful fuzz tests.
-
Set the API Key: Store the key printed in the terminal on the first startup of Ollama in the
CIFUZZ_LLM_API_TOKENenvironment variable:export CIFUZZ_LLM_API_TOKEN="<your-ollama-key>" -
Configure
cifuzz.yaml: Add the following to yourcifuzz.yamlfile.llm:
api-type: "open_ai"
model: "<your_model_name>"
api-url: "<Address of your Ollama server>/v1" #For example: "http://127.0.0.1:11434/v1"
max-tokens: "<your_config_and_model_specific_max_tokens>"
Advanced Configuration
For more granular control, you can use the following environment variables to fine-tune the LLM's behavior.
CIFUZZ_LLM_TEMPERATURE: Temperature for chat completion (e.g.,0.5).CIFUZZ_LLM_MAX_ALTERNATIVES: Maximum number of alternative responses to request. A lower number reduces token usage.CIFUZZ_LLM_API_HEADER_...: Adds custom headers to API requests. Replace...with the header name, using underscores for hyphens (e.g.,CIFUZZ_LLM_API_HEADER_X_My_Header).
# Example:
export CIFUZZ_LLM_TEMPERATURE="0.2"
export CIFUZZ_LLM_MAX_ALTERNATIVES="5"